
RWS 번역 기술 인사이트 2025 - 기술 배워라
팁
작성자
임윤
작성일
2026-02-17 18:50
조회
1196
올타임 레전드 AI 대체 1위 직업을 위한 RWS 번역 기술 인사이트 2025가 나왔습니다.
다운로드: https://www.rws.com/about/translation-technology-insights/
2023년 버전 요약은 여기에 있으니
https://rebtion.net/learnfree/?mod=document&pageid=1&uid=10827
지난번과 어떤 항목이 달라졌나 비교하며 보시는 것도 의미가 있을 것입니다.
2023년 이후 기술적으로는 생성형 AI와 LLM이 비약적인 발전을 이루었고, 경제적으로는 유동성 파티가 종료되었고, 정치적으로는 보호무역주의가 득세하게 되었습니다. 이 상황에서 반가운 보고서가 나왔는데요.
항상 강조하는 것이지만, “작성자”가 누구인지, “왜” 작성했는지 고려하며 읽으시면 좋겠습니다. 저와 RWS는 이해관계가 같지 않으므로 같은 사실을 놓고도 의견이 다를 수밖에 없습니다.
배경 지식
NMT: 인공신경망(Neural Network)을 이용해 문장을 통째로 이해하는 번역에 특화된 AI 기술(기존의 문법을 하나하나 입력하는 규칙 기반 RMT, 의미 단위를 기반으로 연결하는 통계 기반 SMT에서 발전한 것), Google Translate가 여기 속함
LLM: 범용 언어 이해/생성 모델
생성형 AI: 콘텐츠를 생성하는 AI 전체 개념(LLM 포함), ChatGPT, Claude, Gemini, Llama 등
기존 조사 대상인 번역가, 번역회사, 기업(고객사)에 더해, 새로 정부 부문이 추가되었습니다. 원래 기술 발전과 대규모 실직은 역사적으로 세트였고(산업혁명, 이앙법, 우리 세대에서는 닷컴 버블 기억하시면 됨), 정부들이 손가락 빨고 있어봤더니 하등 좋을 것이 없었더라 하는 것도 학습됐기 때문에 기본소득 같은 것이 논의될 것입니다.
일의 본질을 고려하면, 의뢰하는 기업 입장에서는 불황에 매출을 유지하기 위해 번역이 계속 필요합니다. 대부분 자국 내에서 수요는 이미 소진되었고 비교적 저렴한 값으로 시장을 확장할 수 있는 수단이거든요. 신제품을 개발하는 것보다는 번역이 싸게 먹힌다는 뜻입니다.
모내기 테크 발전했다고 사람들이 밥을 끊나요?
모내기에 대체된다는 말은 어불성설입니다. 기술 배워서 다른 생산성 낮은 소작농을 대체하는 부농이 생기죠. 사회 전체가 가진 기술과 개별 인적 자원은 구분해서 생각해야 합니다.
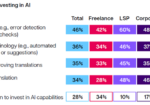
보고서의 흥미로운 부분이 이 지점입니다. 기업과 정부 부문에서 의뢰하는 분량은 그대로거나 늘었는데(약 74%) 번역회사와 번역가는 절반 정도가 고객 수 기준으로 일이 줄었다고 응답한 것입니다. 신규 진입자가 많지 않다는 가정하에(AI대체 올타임 레전드 1위 직업이라는 점을 기억하시길) 누군가 저 자들의 일을 빼앗아가고 있다는 뜻인데요.

늘었다고 주장한 번역가 16%와 번역회사 19%도 눈여겨 보면 좋을 것입니다. 저 집단에 뭔가 다른 특성이 있었을 테니까요.
이 보고서는 Slator의 보고서를 인용하고 자체 조사 결과와 비교하며 해답을 찾아냅니다.
매출 기준, 전체 시장은 2024년에 비해 2% 줄었다(거의 같다)는데, 기술 갖춘 번역회사는 매출이 12% 늘었다는 이야기가 나옵니다.
또한 기술만 단독으로 쓰는 것보다는 인간이 개입하는 것이 여전히 결과물이 낫습니다. (개인 번역가 입장에선 적은 돈이 아니지만) 기업 입장에서는 푼돈을 들여 몇백만 달러의 매출을 늘리고 소송을 방지할 수 있다면, AI의 결과물에 인간을 더하지 않을 이유가 없습니다.
덧붙여, 지난번도 그렇고 RWS 보고서는 항상 중요한 통계를 일부러 누락하는 경향이 있는 듯한데요
번역가 기준,
CAT툴 -> 여전히 1할 정도는 사용하지 않음(어떻게 그럴 수가 있지?)
자동 번역, 용어 관리 도구 -> 여전히 과반수가 사용하지 않음(어떻게? 2)
LLM(챗GPT, 제미나이 등) -> 8할 정도가 손도 안 대봄(어떻게? 세상이 그렇게 난리인데 대체 어떻게? 3)
소프트웨어 번역툴 -> 이것도 8할 정도가 손도 안 대봄(어? 4)
인보이스 도구 -> 안 쓰는 사람이 9할 넘음(어떻게 ?? 그럼 어떻게 사는 거야?)
참고 - 챗GPT로 인보이스 자동화하기: https://rebtion.net/learnfree/?uid=12628&mod=document&pageid=1
그렇다면 번역 워크플로(번역 작업 자체, QA, 용어집 관리 등등)에서 기술은 잘 쓰고 있는가?
“두루 잘 쓰고 있는 사람”이 아무리 좋게 봐줘도 4분의 1도 안 됩니다.
참고로 현행 기술로 가능한 것(일부는 로컬 AI 설치해야 법적으로 문제없이 가능)
- 몇만 단어짜리 번역 프로젝트를 사전에 내용을 전반적으로 요약
- 용어의 경우, 기존 플러그인으로는 단순 언급 빈도와 맥락상 중요도가 일치하지 않음. 단순 빈도로 잡아내면 of, the, a, an 같은 게 상단에 몇십 개 나오고, 한참 뒤에서야 중요한 단어가 나옴. (*물론 해결책이 없는 것은 아니지만...) 여기 더해서 'Master of the Void'처럼 여러 단어로 구성된 용어는 사전에 잡아내기가 더 어려움. LLM으로 처리하면 이런 용어를 사전에 알아낼 수 있음.
- 용어를 사전에 파악하여 자동번역에 반영할 수 있음
- 어조 사전에 지정할 수 있음
여기서 궁금해야 하는 점,
“일이 줄어든 집단은 기술을 쓰는 쪽인가, 버린 쪽인가?”
당연히 데이터가 명확할 텐데 보고서에는 나와있지 않으니 어떻다고 말할 수는 없는데 사실은 다들 아실 것 같습니다.
그렇다면 일이 줄어든다는 당사자들은 이 난관을 타개하기 위해 무슨 대책을 세우고 있는가?
번역가 34%는 AI 기술을 배울 생각조차 없다.
이 보고서에서는 경쟁자를 말려죽일 방법은 이번에도 기술이라고 합니다. RWS는 RWS가 직접 관리하는 AI 기술을 판매하고 있는데, 좋은 기술이지만 개인 번역가가 채택하기에는 단가가 안 나옵니다.
저는 보고서에서 언급된 로컬 LLM을 구동해 보려고 합니다. 챗GPT, 제미나이 같은 것을 내 컴퓨터에 깔아서 쓰는 것이라고 생각하면 됩니다.
기존 NMT와 로컬 LLM은 다른 점이 많습니다.
NMT이 누락이 적음(LLM은 단어를 자연스럽게 빼먹음)
LLM이 맥락을 자세히 ‘사용자 지정’할 수 있음
-> 용어집을 넣거나, 작성자, 목적, 독자를 지정하거나, 분야를 사전 설정
-> “기존 번역”을 학습시켜 내용을 참고하도록 할 수 있음
구체적으로는 협업할 때
"ㅈㅅ 저는 여름이가 고양이인줄 알고 번역했는데 알고 보니 개네요... 님 파트에서 수정하셔야 할듯"
"staff랑 wand 구분해서 번역해주세요 아니 텀베이스에 누가 이걸 둘다 지팡이로 해놨어(내가그랬음)"
이런 불미스런 상황이 발생하는 것을 줄일 수 있다는 것입니다.
? 이거 TM하고 다른가요?
다릅니다. TM은 단순히 일치하는 단어만 불러올 수 있는 반면 기존 번역을 학습시키면 줄거리, 기능, 맥락이 함께 학습됩니다. 이것을 향후 번역에 직접 반영할 수는 없습니다.
? 이거 챗GPT(chat.openai.com)에 때려넣으면 되나요?
법적으로도 기술적으로도 안됩니다,
법적으로는 제3자에 제공하는 것이라서 안 되고, 기술적으로는 기억력 문제 때문에 안 됩니다. 기억을 유지하는 데 돈이 상당히 들어가기 때문에 openai에서 기억의 총량을 제한해 놨습니다. 이를 해결하려면 로컬(번역가 집)에 LLM을 설치하고 기억을 유지해야 합니다.
? 법적으로 문제 없나요?
랜선 뽑아버려도 작동하는 것이라 ‘제3자에게 내용 제공하지 말 것’이라는 조항에 위반되지 않습니다.
이 동네는 본인이 서버 굴리고 소프트웨어 개발 단독기술로 먹고 사는 것이 가능한 사람과 포맷, 화면캡처 못하는 사람이 같이 구르고 있으니, 누가 일이 줄어들었다는 말은 그냥 재미로 들으시면 됩니다. 보통 집에서 혼자 일해 모르지만, 번역가 여럿을 물리적 공간에 같이 몰아넣고 작업 방식을 관찰할 기회가 생긴다면 대부분 납득이 갈 것입니다.
어쨌든 이번에는 이런 걸 직접 해보고 있고, 활용 방안은 천천히 소개해 보도록 하겠습니다.
10년, 20년, 30년 전에도 항상 ‘10년 뒤’에는 AI에 대체될 것이라는 소리를 꿋꿋하게 들으며(...) 벼랑끝 심정으로 살아와서 일이 줄어든다는 별로 걱정은 안 됩니다. 이해하는 분만 이해하겠지만, 시간 상한과 정부가 이만큼만 벌라고 정해놓은 소득 상한이 먼저 문제가 될 겁니다.
다운로드: https://www.rws.com/about/translation-technology-insights/
2023년 버전 요약은 여기에 있으니
https://rebtion.net/learnfree/?mod=document&pageid=1&uid=10827
지난번과 어떤 항목이 달라졌나 비교하며 보시는 것도 의미가 있을 것입니다.
2023년 이후 기술적으로는 생성형 AI와 LLM이 비약적인 발전을 이루었고, 경제적으로는 유동성 파티가 종료되었고, 정치적으로는 보호무역주의가 득세하게 되었습니다. 이 상황에서 반가운 보고서가 나왔는데요.
항상 강조하는 것이지만, “작성자”가 누구인지, “왜” 작성했는지 고려하며 읽으시면 좋겠습니다. 저와 RWS는 이해관계가 같지 않으므로 같은 사실을 놓고도 의견이 다를 수밖에 없습니다.
배경 지식
NMT: 인공신경망(Neural Network)을 이용해 문장을 통째로 이해하는 번역에 특화된 AI 기술(기존의 문법을 하나하나 입력하는 규칙 기반 RMT, 의미 단위를 기반으로 연결하는 통계 기반 SMT에서 발전한 것), Google Translate가 여기 속함
LLM: 범용 언어 이해/생성 모델
생성형 AI: 콘텐츠를 생성하는 AI 전체 개념(LLM 포함), ChatGPT, Claude, Gemini, Llama 등
기존 조사 대상인 번역가, 번역회사, 기업(고객사)에 더해, 새로 정부 부문이 추가되었습니다. 원래 기술 발전과 대규모 실직은 역사적으로 세트였고(산업혁명, 이앙법, 우리 세대에서는 닷컴 버블 기억하시면 됨), 정부들이 손가락 빨고 있어봤더니 하등 좋을 것이 없었더라 하는 것도 학습됐기 때문에 기본소득 같은 것이 논의될 것입니다.
일의 본질을 고려하면, 의뢰하는 기업 입장에서는 불황에 매출을 유지하기 위해 번역이 계속 필요합니다. 대부분 자국 내에서 수요는 이미 소진되었고 비교적 저렴한 값으로 시장을 확장할 수 있는 수단이거든요. 신제품을 개발하는 것보다는 번역이 싸게 먹힌다는 뜻입니다.
모내기 테크 발전했다고 사람들이 밥을 끊나요?
모내기에 대체된다는 말은 어불성설입니다. 기술 배워서 다른 생산성 낮은 소작농을 대체하는 부농이 생기죠. 사회 전체가 가진 기술과 개별 인적 자원은 구분해서 생각해야 합니다.
보고서의 흥미로운 부분이 이 지점입니다. 기업과 정부 부문에서 의뢰하는 분량은 그대로거나 늘었는데(약 74%) 번역회사와 번역가는 절반 정도가 고객 수 기준으로 일이 줄었다고 응답한 것입니다. 신규 진입자가 많지 않다는 가정하에(AI대체 올타임 레전드 1위 직업이라는 점을 기억하시길) 누군가 저 자들의 일을 빼앗아가고 있다는 뜻인데요.
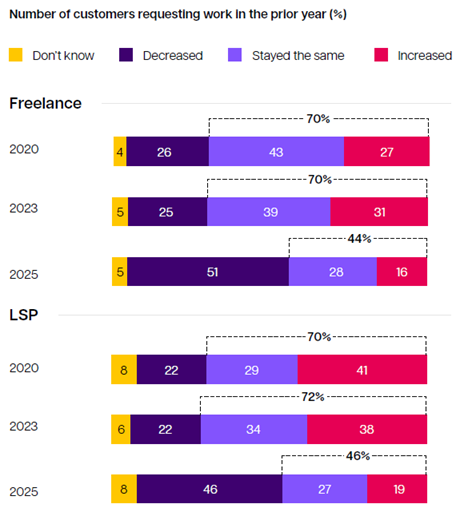
늘었다고 주장한 번역가 16%와 번역회사 19%도 눈여겨 보면 좋을 것입니다. 저 집단에 뭔가 다른 특성이 있었을 테니까요.
이 보고서는 Slator의 보고서를 인용하고 자체 조사 결과와 비교하며 해답을 찾아냅니다.
매출 기준, 전체 시장은 2024년에 비해 2% 줄었다(거의 같다)는데, 기술 갖춘 번역회사는 매출이 12% 늘었다는 이야기가 나옵니다.
또한 기술만 단독으로 쓰는 것보다는 인간이 개입하는 것이 여전히 결과물이 낫습니다. (개인 번역가 입장에선 적은 돈이 아니지만) 기업 입장에서는 푼돈을 들여 몇백만 달러의 매출을 늘리고 소송을 방지할 수 있다면, AI의 결과물에 인간을 더하지 않을 이유가 없습니다.
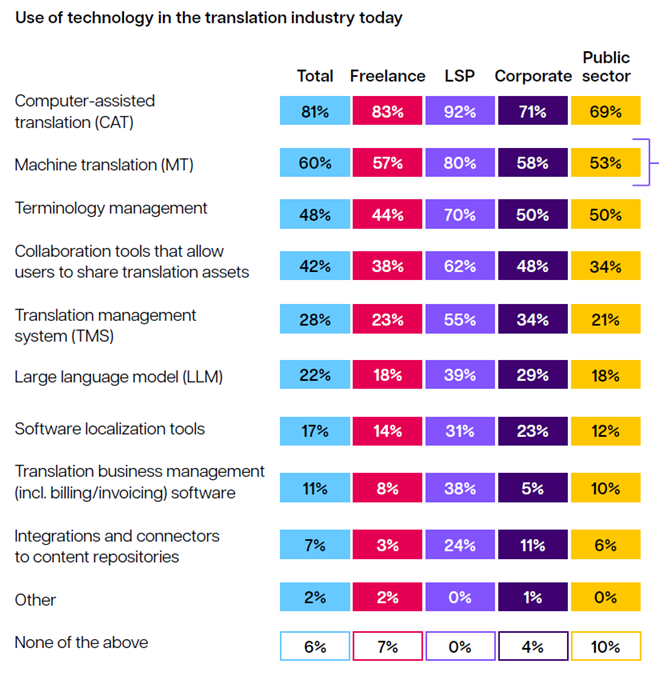
덧붙여, 지난번도 그렇고 RWS 보고서는 항상 중요한 통계를 일부러 누락하는 경향이 있는 듯한데요
번역가 기준,
CAT툴 -> 여전히 1할 정도는 사용하지 않음(어떻게 그럴 수가 있지?)
자동 번역, 용어 관리 도구 -> 여전히 과반수가 사용하지 않음(어떻게? 2)
LLM(챗GPT, 제미나이 등) -> 8할 정도가 손도 안 대봄(어떻게? 세상이 그렇게 난리인데 대체 어떻게? 3)
소프트웨어 번역툴 -> 이것도 8할 정도가 손도 안 대봄(어? 4)
인보이스 도구 -> 안 쓰는 사람이 9할 넘음(어떻게 ?? 그럼 어떻게 사는 거야?)
참고 - 챗GPT로 인보이스 자동화하기: https://rebtion.net/learnfree/?uid=12628&mod=document&pageid=1
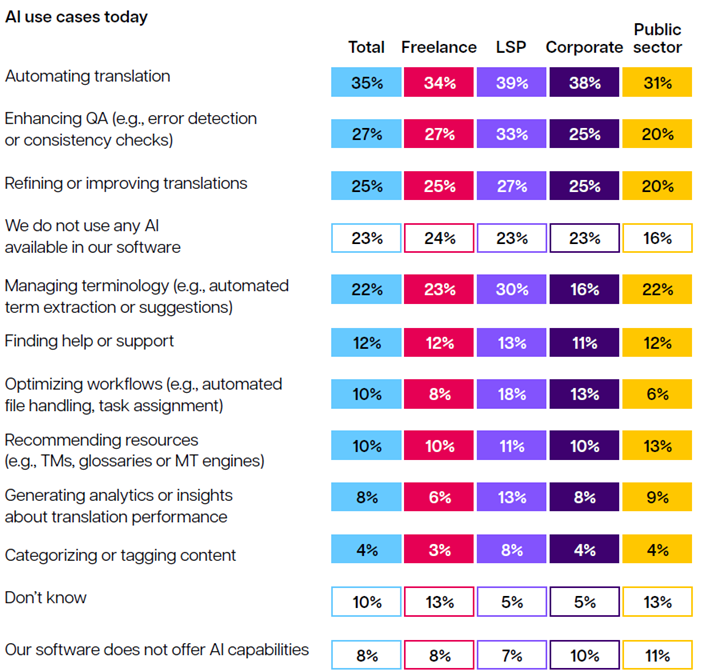
그렇다면 번역 워크플로(번역 작업 자체, QA, 용어집 관리 등등)에서 기술은 잘 쓰고 있는가?
“두루 잘 쓰고 있는 사람”이 아무리 좋게 봐줘도 4분의 1도 안 됩니다.
참고로 현행 기술로 가능한 것(일부는 로컬 AI 설치해야 법적으로 문제없이 가능)
- 몇만 단어짜리 번역 프로젝트를 사전에 내용을 전반적으로 요약
- 용어의 경우, 기존 플러그인으로는 단순 언급 빈도와 맥락상 중요도가 일치하지 않음. 단순 빈도로 잡아내면 of, the, a, an 같은 게 상단에 몇십 개 나오고, 한참 뒤에서야 중요한 단어가 나옴. (*물론 해결책이 없는 것은 아니지만...) 여기 더해서 'Master of the Void'처럼 여러 단어로 구성된 용어는 사전에 잡아내기가 더 어려움. LLM으로 처리하면 이런 용어를 사전에 알아낼 수 있음.
- 용어를 사전에 파악하여 자동번역에 반영할 수 있음
- 어조 사전에 지정할 수 있음
여기서 궁금해야 하는 점,
“일이 줄어든 집단은 기술을 쓰는 쪽인가, 버린 쪽인가?”
당연히 데이터가 명확할 텐데 보고서에는 나와있지 않으니 어떻다고 말할 수는 없는데 사실은 다들 아실 것 같습니다.
그렇다면 일이 줄어든다는 당사자들은 이 난관을 타개하기 위해 무슨 대책을 세우고 있는가?
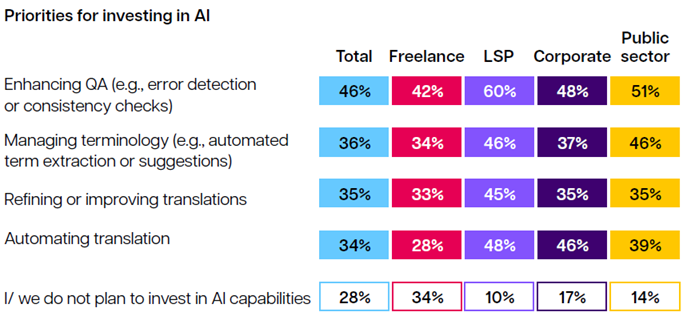
번역가 34%는 AI 기술을 배울 생각조차 없다.
이 보고서에서는 경쟁자를 말려죽일 방법은 이번에도 기술이라고 합니다. RWS는 RWS가 직접 관리하는 AI 기술을 판매하고 있는데, 좋은 기술이지만 개인 번역가가 채택하기에는 단가가 안 나옵니다.
저는 보고서에서 언급된 로컬 LLM을 구동해 보려고 합니다. 챗GPT, 제미나이 같은 것을 내 컴퓨터에 깔아서 쓰는 것이라고 생각하면 됩니다.
기존 NMT와 로컬 LLM은 다른 점이 많습니다.
NMT이 누락이 적음(LLM은 단어를 자연스럽게 빼먹음)
LLM이 맥락을 자세히 ‘사용자 지정’할 수 있음
-> 용어집을 넣거나, 작성자, 목적, 독자를 지정하거나, 분야를 사전 설정
-> “기존 번역”을 학습시켜 내용을 참고하도록 할 수 있음
구체적으로는 협업할 때
"ㅈㅅ 저는 여름이가 고양이인줄 알고 번역했는데 알고 보니 개네요... 님 파트에서 수정하셔야 할듯"
"staff랑 wand 구분해서 번역해주세요 아니 텀베이스에 누가 이걸 둘다 지팡이로 해놨어(내가그랬음)"
이런 불미스런 상황이 발생하는 것을 줄일 수 있다는 것입니다.
? 이거 TM하고 다른가요?
다릅니다. TM은 단순히 일치하는 단어만 불러올 수 있는 반면 기존 번역을 학습시키면 줄거리, 기능, 맥락이 함께 학습됩니다. 이것을 향후 번역에 직접 반영할 수는 없습니다.
? 이거 챗GPT(chat.openai.com)에 때려넣으면 되나요?
법적으로도 기술적으로도 안됩니다,
법적으로는 제3자에 제공하는 것이라서 안 되고, 기술적으로는 기억력 문제 때문에 안 됩니다. 기억을 유지하는 데 돈이 상당히 들어가기 때문에 openai에서 기억의 총량을 제한해 놨습니다. 이를 해결하려면 로컬(번역가 집)에 LLM을 설치하고 기억을 유지해야 합니다.
? 법적으로 문제 없나요?
랜선 뽑아버려도 작동하는 것이라 ‘제3자에게 내용 제공하지 말 것’이라는 조항에 위반되지 않습니다.
이 동네는 본인이 서버 굴리고 소프트웨어 개발 단독기술로 먹고 사는 것이 가능한 사람과 포맷, 화면캡처 못하는 사람이 같이 구르고 있으니, 누가 일이 줄어들었다는 말은 그냥 재미로 들으시면 됩니다. 보통 집에서 혼자 일해 모르지만, 번역가 여럿을 물리적 공간에 같이 몰아넣고 작업 방식을 관찰할 기회가 생긴다면 대부분 납득이 갈 것입니다.
어쨌든 이번에는 이런 걸 직접 해보고 있고, 활용 방안은 천천히 소개해 보도록 하겠습니다.
10년, 20년, 30년 전에도 항상 ‘10년 뒤’에는 AI에 대체될 것이라는 소리를 꿋꿋하게 들으며(...) 벼랑끝 심정으로 살아와서 일이 줄어든다는 별로 걱정은 안 됩니다. 이해하는 분만 이해하겠지만, 시간 상한과 정부가 이만큼만 벌라고 정해놓은 소득 상한이 먼저 문제가 될 겁니다.

임윤
ㆍ
2024.10.19
ㆍ
추천
72
ㆍ
조회
9498
팁
ㆍ
임윤
ㆍ
2026.02.17
ㆍ
추천
22
ㆍ
조회
1196
팁
ㆍ
임윤
ㆍ
2026.02.09
ㆍ
추천
5
ㆍ
조회
690
컴퓨터/잡무 관리 (1)
팁
ㆍ
임윤
ㆍ
2026.01.20
ㆍ
추천
22
ㆍ
조회
1160
CAT툴
ㆍ
임윤
ㆍ
2026.01.10
ㆍ
추천
11
ㆍ
조회
809
챗GPT로 인보이스 자동화하기 (1)
팁
ㆍ
임윤
ㆍ
2026.01.10
ㆍ
추천
8
ㆍ
조회
1046
CAT툴
ㆍ
임윤
ㆍ
2025.12.15
ㆍ
추천
7
ㆍ
조회
814

임윤
ㆍ
2025.11.12
ㆍ
추천
21
ㆍ
조회
1016
CAT툴
ㆍ
임윤
ㆍ
2025.11.06
ㆍ
추천
5
ㆍ
조회
1048
CAT툴
ㆍ
임윤
ㆍ
2025.11.05
ㆍ
추천
6
ㆍ
조회
972
CAT툴
ㆍ
임윤
ㆍ
2025.11.03
ㆍ
추천
8
ㆍ
조회
961
팁
ㆍ
임윤
ㆍ
2025.10.14
ㆍ
추천
9
ㆍ
조회
1374

CAT툴
ㆍ
임윤
ㆍ
2025.10.12
ㆍ
추천
5
ㆍ
조회
978
팁
ㆍ
임윤
ㆍ
2025.09.18
ㆍ
추천
9
ㆍ
조회
1270
CAT툴
ㆍ
임윤
ㆍ
2025.09.12
ㆍ
추천
10
ㆍ
조회
1022
팁
ㆍ
임윤
ㆍ
2025.09.11
ㆍ
추천
7
ㆍ
조회
1236
팁
ㆍ
임윤
ㆍ
2025.09.04
ㆍ
추천
6
ㆍ
조회
1226
CAT툴
ㆍ
임윤
ㆍ
2025.07.29
ㆍ
추천
10
ㆍ
조회
1299
얼마 전 에이전시의 의뢰로 모 고객사 정규 프로젝트 론칭을 위한 한국어 팀 구성 작업에 참여한 적이 있었습니다.
이 고객사 일을 주기적으로 해 줄 작업자를 선정해야 해서 어림잡아 20여명 분량의 샘테+프로필/이력서를 검토해야 했었는데요, 파일럿 기간 동안 주로 번역을 담당해 주셨던 분 이력서를 보고 말 그대로 눈이 튀어나올 뻔 했습니다. 무려 제가 태어났던 해에 >>대학교에 입학<하셨더라구요;;;(참고로 저는 제5공화국 시기 출생입니다) 아주아주 간혹 다소 클래식한 단어를 사용하셨던 경향은 있지만(빗대어 말하자면 '다음 주'를 '차주'라고 쓰시는 것 같은) 캣툴 사용이나 태그/플레이스홀더 처리는 물론이고 Jira 같은 협업 툴에 ticket raise 하는것도 능숙하셔서 이정도 연배가 있는 분일거라고는 상상도 못했거든요. 제 안의 편견을 크게 반성하며...(배우고 때때로 익히는 게 기쁘기는 고사하고 원래 하던대로 하던것만 하려는 게 인간의 본성이긴 하겠지만) 역시 롱런하려면 끊임없이 배워야겠다고 다짐하는 계기가 되었더랬습니다. 유익한 리포트 업데이트해 주셔서 감사합니다.
헉... 듣던 음악 끄고 심각하게 읽었습니다 인사이트 리포트 업데이트 해주셔서 감사합니다(--)(__) 새해 복 많이 받으세용
오... 자세를 고쳐 정자세로 읽었습니다. 이렇게 귀한 인사이트 나눠주시다니.. 항상 감사하며 읽고 있어요. 원문 보고서도 살펴봐야겠네요! 새해 복 많이 받으세요.